How to create, find and eliminate deadlocks
Deadlocks are typically encountered in high-load scenarios or in complex concurrent transactions. And the worst part is, you probably won’t see them until you’re live in production. Luckily, finding and solving deadlock issues isn’t as complicated as it may sound. All it takes is a bit of logging and patience, along with some basic know-how of how locking mechanisms work in SQL Server.
What’s a deadlock?
A deadlock occurs when two processes are waiting for the same resources – and both of these processes are waiting for the other to finish.
Imagine the following example of a banking database: Alice and Bob have bank accounts, and they want to send each other money. The process of sending money from one account to another involves two bookings that have to be
atomic, i.e. run in a transaction. Because if the server or network connection fail after only half the operation has been completed, the balances would be off, and somebody would probably end up having a pretty bad day.
Alice starts off by moving $1000 to Bob’s account:
(process 1)
BEGIN TRANSACTION;
UPDATE banking.accounts
SET balance=balance-1000
WHERE account='Alice';
UPDATE banking.accounts
SET balance=balance+1000
WHERE account='Bob';
COMMIT TRANSACTION;
But what if Bob, only a millisecond after Alice, clicks the “Send” button on his Internet banking web page, to send $500 to Alice? The code would look like this:
(process 2)
BEGIN TRANSACTION;
UPDATE banking.accounts
SET balance=balance-500
WHERE account='Bob';
UPDATE banking.accounts
SET balance=balance+500
WHERE account='Alice';
COMMIT TRANSACTION;
Here’s a timeline of what happens:
- Alice takes $1000 from her account (process 1). This creates a lock on her account (so nobody else can change the balance, in case we need to roll back the transaction later).
- Bob takes $500 from his account (process 2), placing a lock on his account.
- Alice (process 1) is now waiting for the Bob (process 2) to commit his transaction, so the lock on Bob’s account is released, before she can complete the transfer.
- At the same time, Bob (process 2) is waiting for Alice (process 1) to commit her transaction.
In the end, both Alice and Bob are waiting for each other to complete their respective transactions, and they could technically wait forever. This is where the deadlock monitor, a system process in SQL Server, steps in an kills (rolls back) the process that has done the least amount of work. The killed process, known as the deadlock victim, receives the following error message:
Msg 1205, Level 13, State 51, Line 1
Transaction (Process ID 73) was deadlocked on lock resources with
another process and has been chosen as the deadlock victim.
Rerun the transaction.
In the example above, the objects of the deadlock are two rows in the same table, but the object of a deadlock can be a number of different things – tables, pages, rows, schemas, locks, even chunks of memory or worker threads. However, wer’re going to limit our scope to the most common kind, database objects.
Using SQL Server Profiler to identify deadlocks
A trace in SQL Server Profiler can give you details as to what objects are deadlocked. Start off from a blank template, then, under “Locks”, check the “Deadlock graph”, “Lock: Deadlock” and “Lock: Deadlock Chain” events.
You can run this trace interactively (with the Profiler window open) or in the background, as a server-side trace if you want to keep logging for a longer time. Just remember to stop your server-side trace once you’re done. A lot of people will tell you that a long-running trace takes a lot more resources if it runs interactively in Profiler than as a background trace, but I haven’t verified this myself.
Once you find deadlock events, you can view the dependency graph in Profiler to find out which objects were involved. From that, you can hopefully deduce what procedure or queries to tune. If you can’t, simply add those events as well, but be aware that your trace log can fill up pretty fast if you do.
How to avoid deadlocks
As you’ll understand by now, deadlocks are naturally occurring in databases, and the more transactions you run through it, the more likely a deadlock is to happen. So mostly, there is no sure-fire way of completely eliminating deadlocks. The best you can do is a kind of “harm reduction”, where you a) minimize the number of deadlocks, and b) handle those that happen, by trapping deadlocks and rerunning the transactions.
Guidelines for minimizing the number of deadlocks
In my personal order of preference:
- Deadlocks (nearly) always happen in SQL transactions. Time is a factor, so keep transactions as short as possible. Optimize indexes for performance on critical tables. And never, ever, leave an uncommitted transaction waiting for user input.
- For all operations that are atomic, keep the size of the operation to an absolute minimum, as far as your situation allows for.
- Use locking hints to place more specific locks. Lock all your resources as quickly as possible.
- Make sure all your code places locks in the same order.
- Try different isolation levels.
How to handle a deadlock
Deadlocks can be trapped using a TRY-CATCH block. If your transaction is deadlocked, it is rolled back to the point of the BEGIN TRANSACTION statement.
Locking order
If you always lock objects in the
same order, you will significantly reduce the risk of those objects being part of a deadlock. To look at the banking example above, if we always make the transfers in the alphabetical order of the account holder’s name, here’s how Bob’s transfer (process 2) would have looked:
BEGIN TRANSACTION;
-- 'Alice'<'Bob', so her account goes first:
UPDATE banking.accounts
SET balance=balance+500
WHERE account='Alice';
UPDATE banking.accounts
SET balance=balance-500
WHERE account='Bob';
COMMIT TRANSACTION;
With this new setup, let’s go through the timeline again:
- Alice takes $1000 from her account (process 1). This creates a lock on her account.
- Bob (process2) waits for Alice.
- Alice adds $1000 to Bob’s account (process 1).
- Alice (process 1) commits her transaction.
- Bob (process 2) now adds $500 to Alice’s account.
- Bob (process 2) removes $500 from his account.
- Bob commits his transaction.
Locking hints
Using locking hints, it’s possible to tell SQL Server what kind of locks to place. This is practical when you’re handling lock escalation. Lock escalation occurs when a lock is converted, for instance from a shared lock to an update or exclusive lock. Lock escalations happen all the time, and mostly, SQL Server gets it right. However, it can only guess what you want to accomplish, so you can help it along by explicitly specifying what types of locks and what granularity you want.
Depending on your query, an aggressive lock (exclusive table or schema lock) may work better or worse than a relaxed strategy (intent shared, row lock). The best strategy is very dependent on how your transaction looks and how much work it does.
Locking hints are defined with the tables in a query:
...
FROM dbo.table_a AS a WITH (TABLOCKX, HOLDLOCK)
LEFT JOIN dbo.table_b AS b WITH (NOLOCK) ON ...
Here are some common locking hints
- TABLOCK and TABLOCKX: Table lock and exclusive table lock. One lock is placed on the entire table.
- PAGLOCK: Places a page lock. A page is an 8 kB unit of storage.
- ROWLOCK: Locks individual rows. Very fine-grained, should only be used on very small quantities of data.
- UPDLOCK: Update lock, allows other processes to view locked data, but not change it.
- NOLOCK: Applies to SELECT statements only. Does not place any lock and does not honor any existing locks from other processes.
A locking hint-based solution to the deadlock example above could be placing initial locks on
both rows before performing the two updates:
BEGIN TRANSACTION;
--- Place a rowlock on each of the two rows and hold these
--- locks for the remainder of the transaction.
SET @dummy=SUM(balance)
FROM banking.accounts WITH (ROWLOCK, HOLDLOCK)
WHERE account IN ('Alice', 'Bob')
UPDATE banking.accounts
SET balance=balance-1000
WHERE account='Alice';
UPDATE banking.accounts
SET balance=balance+1000
WHERE account='Bob';
COMMIT TRANSACTION;
This way, both accounts are locked the instant we start the procedure. The HOLDLOCK hint makes sure that the two locks are held until we commit or roll back the transaction.
Deadlock priority
Normally, when a deadlock occurs, the transaction that has accomplished the least amount of work is the one that is chosen as the deadlock victim, i.e. rolled back with an error message.
However, you can assign different priorities to different transactions, depending on what they do or how critical they are.
SET DEADLOCK_PRIORITY HIGH
Valid parameters are LOW, NORMAL, HIGH, or numeric values between -10 and 10. A lower number or LOW means that there is a higher probability that the transaction will be selected as the victim in a deadlock.
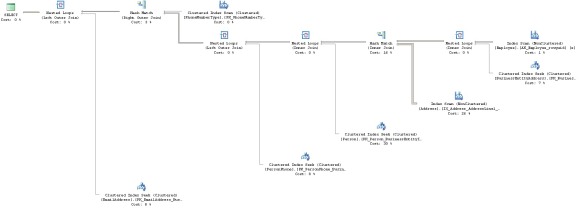
 Clustered index seek,
Clustered index seek,  index seek
index seek Clustered index scan,
Clustered index scan,  index scan
index scan Table scanIf this operator turns up, you’ve forgotten to create a clustered index to your table. It goes through the entire table, top-to-bottom, which is resource-consuming and results in very poor performance and takes a heavy toll on the I/O. A table scan only happens when there is no suitable index available to complete the query.
Table scanIf this operator turns up, you’ve forgotten to create a clustered index to your table. It goes through the entire table, top-to-bottom, which is resource-consuming and results in very poor performance and takes a heavy toll on the I/O. A table scan only happens when there is no suitable index available to complete the query. Nested loops
Nested loops Merge join
Merge join Hash match, hash join
Hash match, hash join Sort
Sort